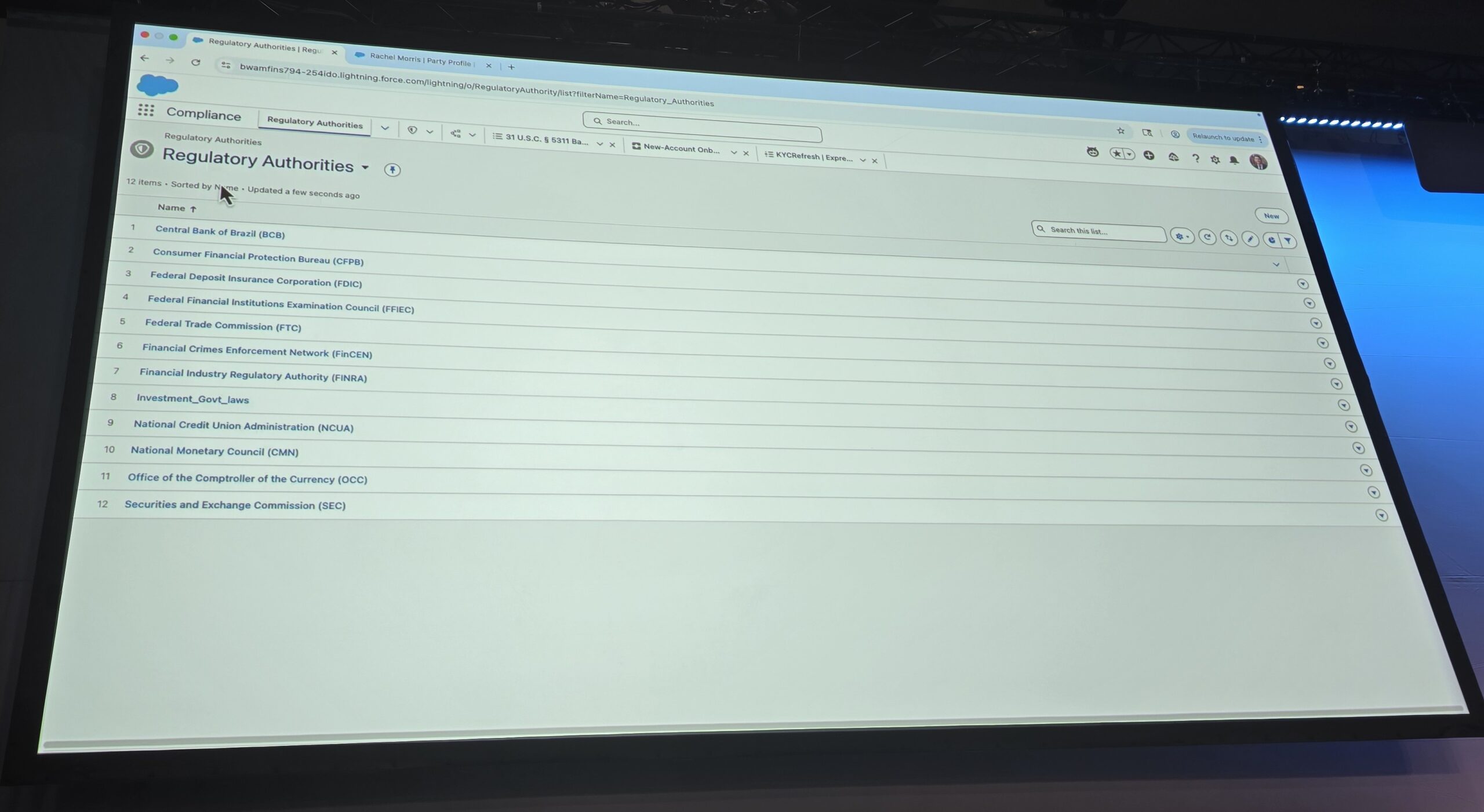
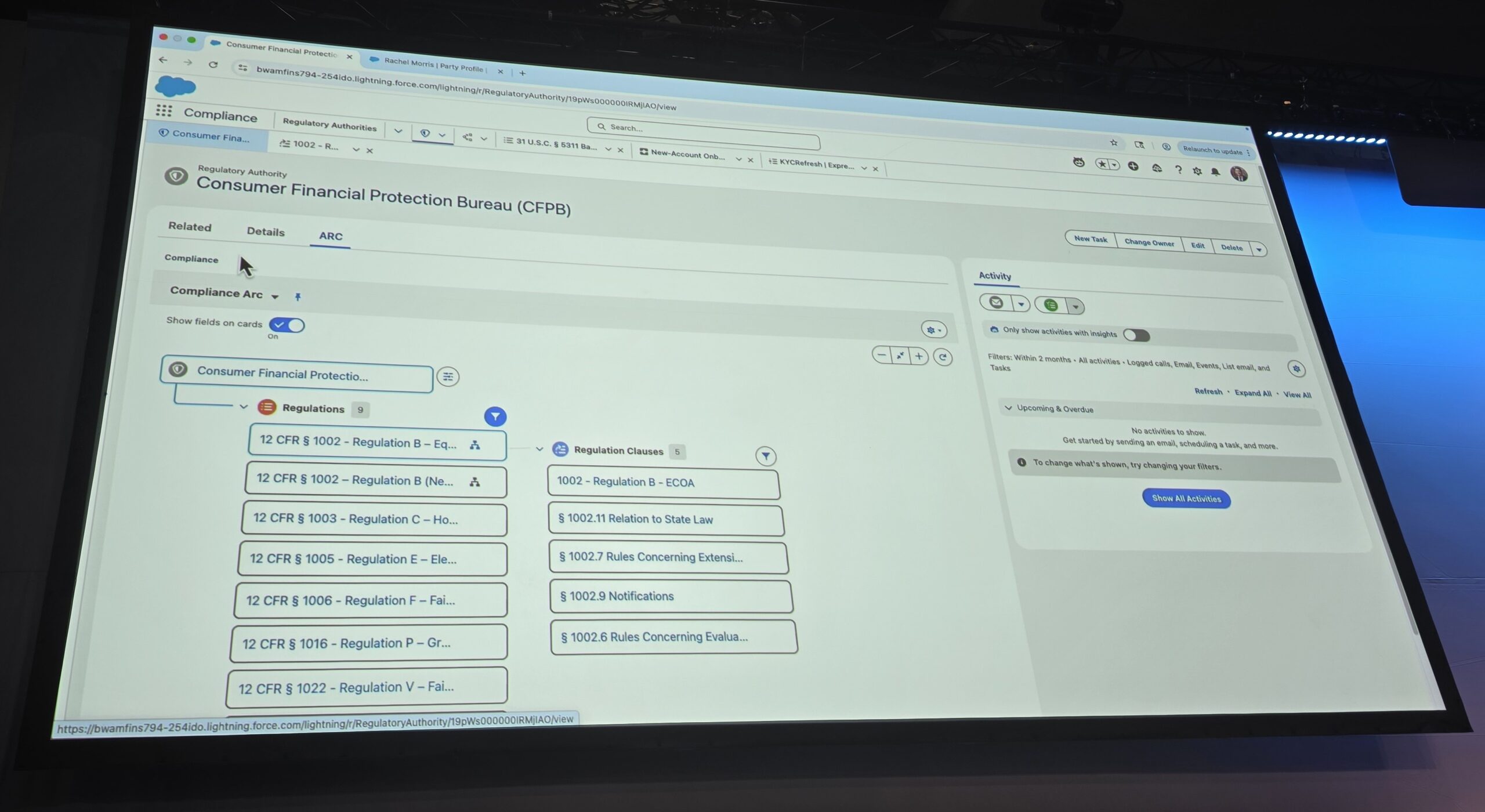
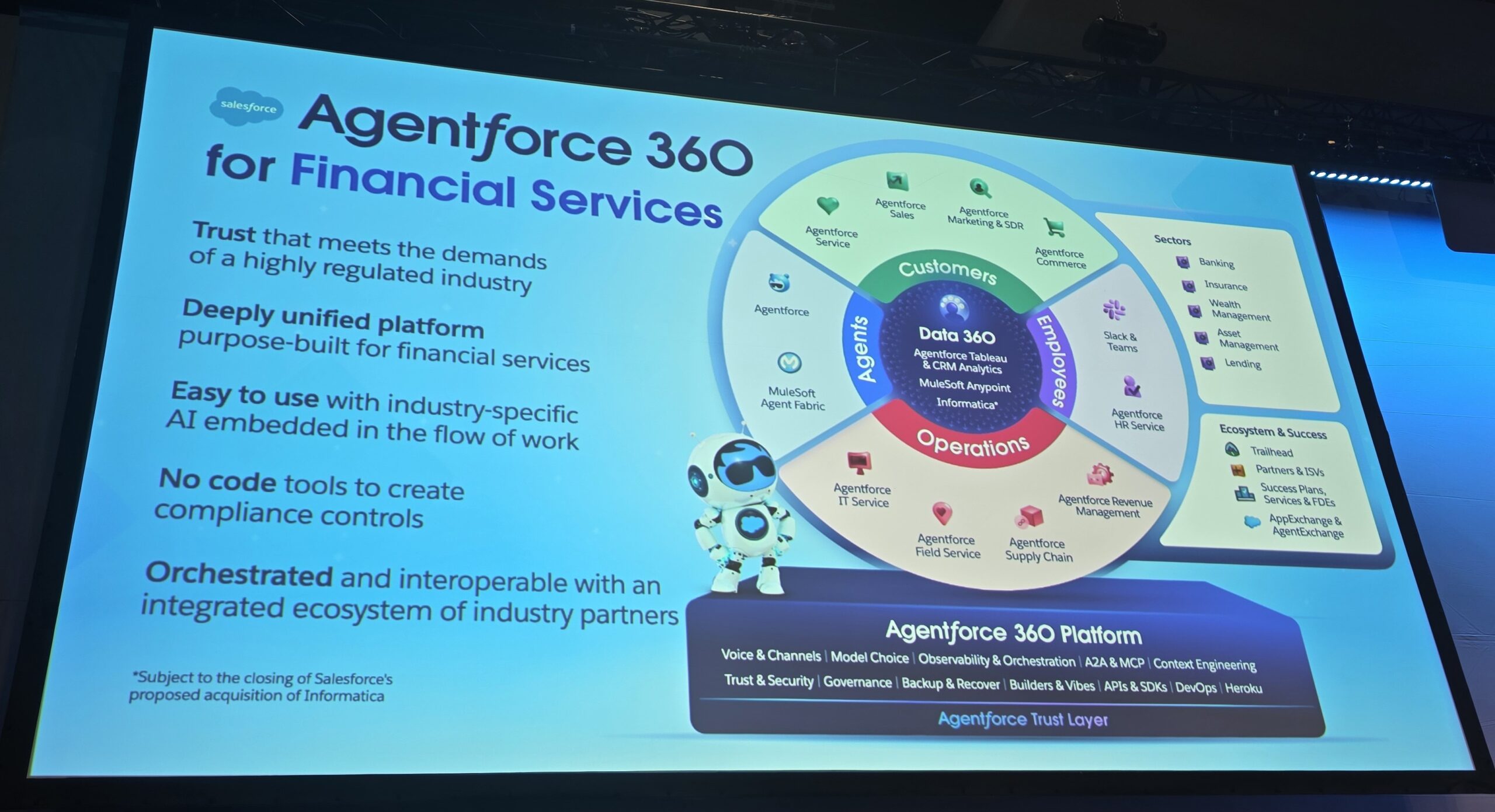
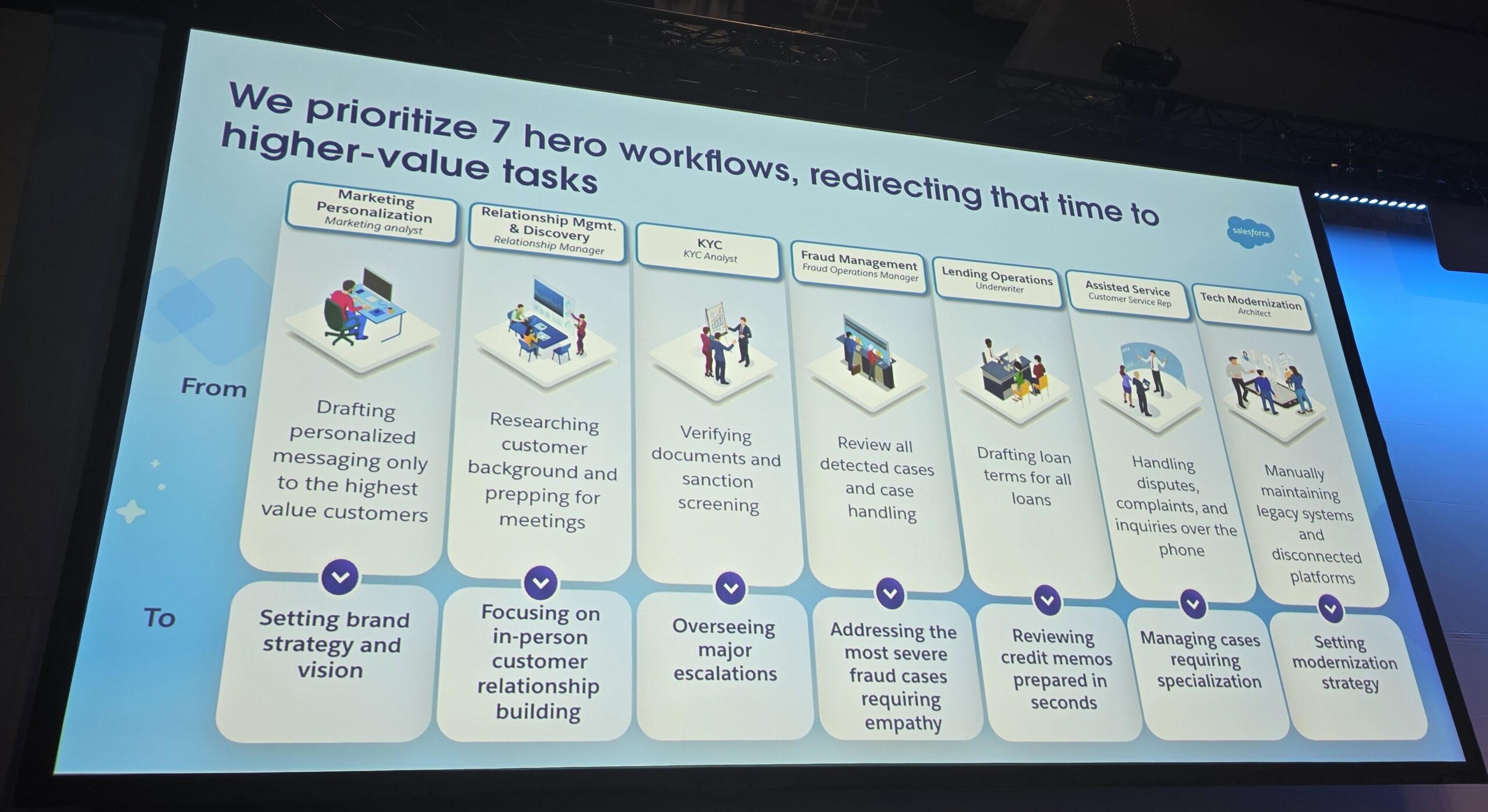
Preface.
Before I get going on the subject, I want to make a clear distinction. I am not talking about AI as a financial investment. As it currently stands, that side of things looks as if it is setting itself up quite nicely for a nasty correction, and it is already showing all the hallmarks of another ‘Tulips’ or .com moment. But I do not know enough about that world to comment in any depth. 1
What I am talking about here is the technological adjustment that will happen when the investment rounds in AI finish, the speculative phase ends, and the technology has to make solid money day after day.
As the media cycle spins on, we keep hearing talk of the AI bubble collapsing, which then becomes talk of the collapse of AI itself. Now I know I swore I was not going to write another thought piece on AI, but here we are.
I don’t think we are going to see a collapse of AI as a technology. We may well see the collapse of a few overextended companies, but what I think we are far more likely to see is a rationalisation of the excess of AI features.
Rather than the dramatic collapse that some people seem to want to hype up, I think it will look much more like what we saw with JavaScript. Those who recognise the word “Netscape” will remember when JavaScript first arrived in browsers and did everything. Then it was discovered that it did everything badly and rather messily, and it was wildly overused. It was clamped down on hard and fell out of favour for a while. Then people realised that actually, this kind of functionality was really useful, as long as it was applied properly, limited in the right places and optimised where it made sense. From there, it grew and grew until it became more popular than ever. I think we are heading for the same kind of correction with AI.
I also think that a lot of the components that make up what people think of as AI will become more visible in their own right. At the moment, most people only think of the big, flashy parts, like Large Language Models. I suspect that things like vector databases will become far more visible. Alternative database technologies will also continue to grow in popularity, particularly NoSQL. Orchestration and model routing will also become things that are simply built into other systems as standard.
What I really think will happen is that people will build applications and want the power that a full AI stack offers, but they will not want to pay full AI prices for everything. If your cloud costs are already around ten thousand a month, you are not going to want to add another ten to fifteen thousand just for the AI layer. You will want it to be cheaper, more targeted, and you will only want to pay for what it is genuinely worth.
Because of that, I think we will see a breakup of the big, all-encompassing AI platforms, leaving only a few players who can truly operate at global scale, such as Salesforce, OpenAI and Google. The rest of us will use smaller, more focused AI components to deliver the specific features we actually need.
I have mentioned this example before, but claims evaluation is still my favourite. You only need a very small language model and your own local data store to do a serious job of evaluating whether claims are fraudulent or not. You do not need it to hold a full conversation. You do not need chat prompts and all the engineering that goes with that. It is still AI driven, but it is focused and cost-effective.
I think we will see more and more of this approach as people take only what they need, rather than paying for vast, Agentic systems that do everything, cost too much, and deliver too little in return.
- Shares generally terrify me, as I am risk averse, which is why my total shareholding is 3 Games Workshop shares, which I mainly have for the amusement value. [↩]