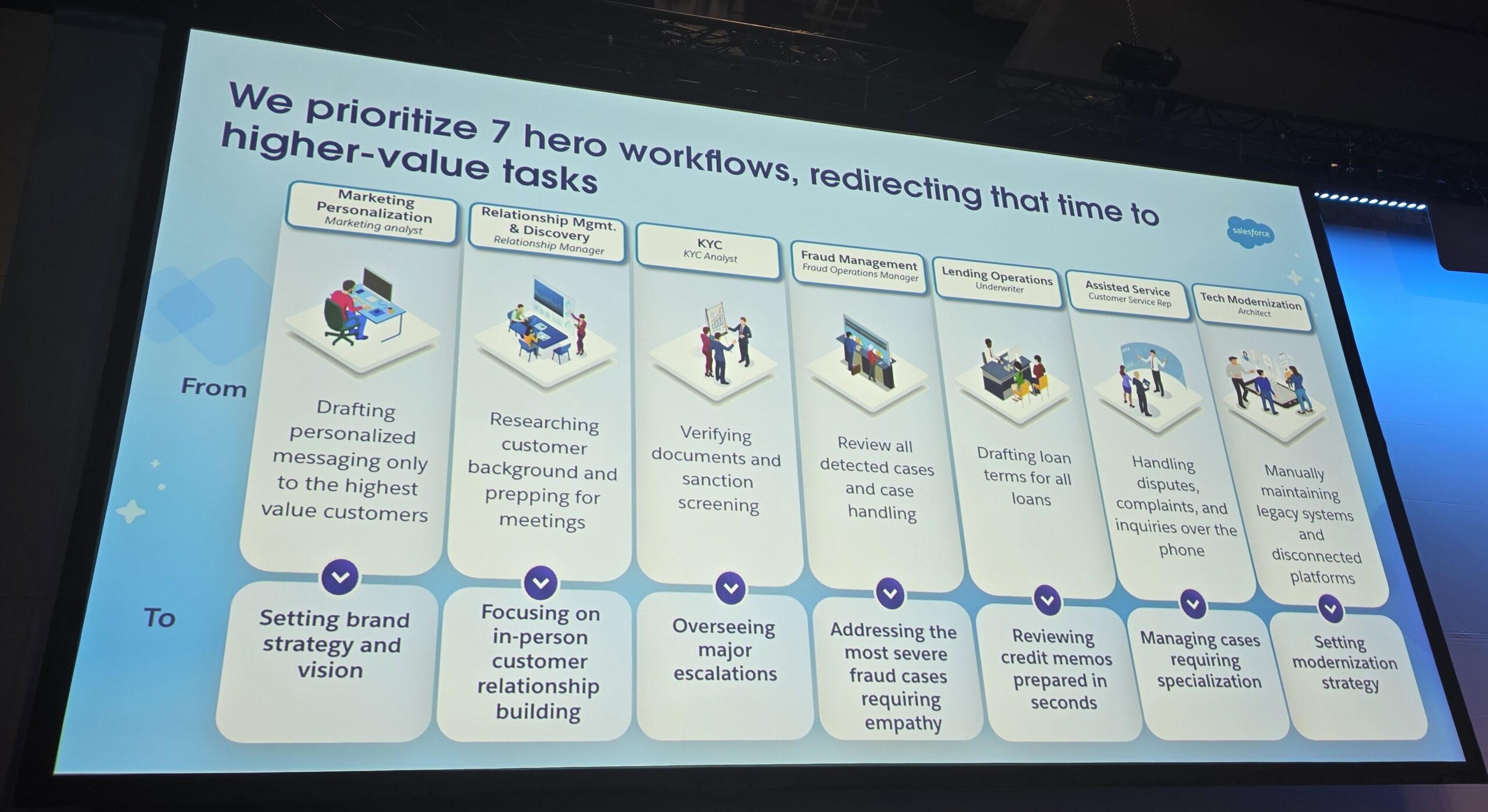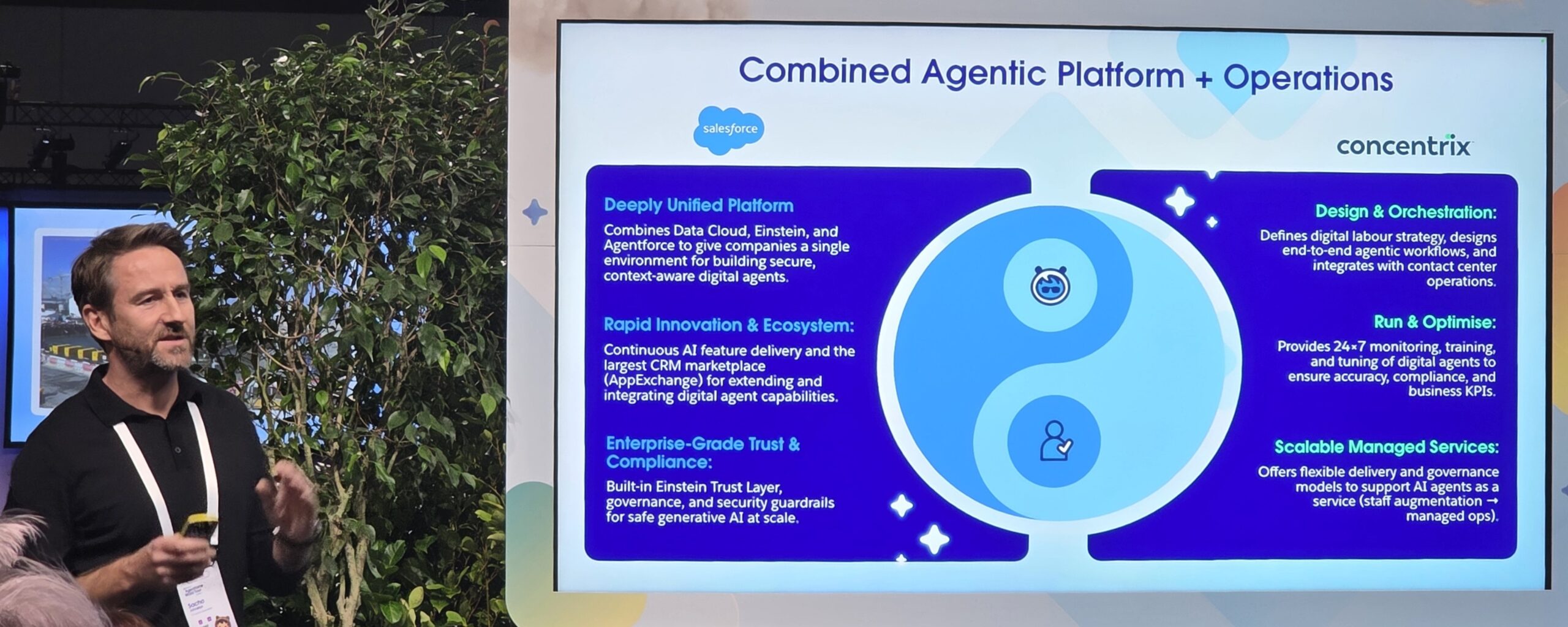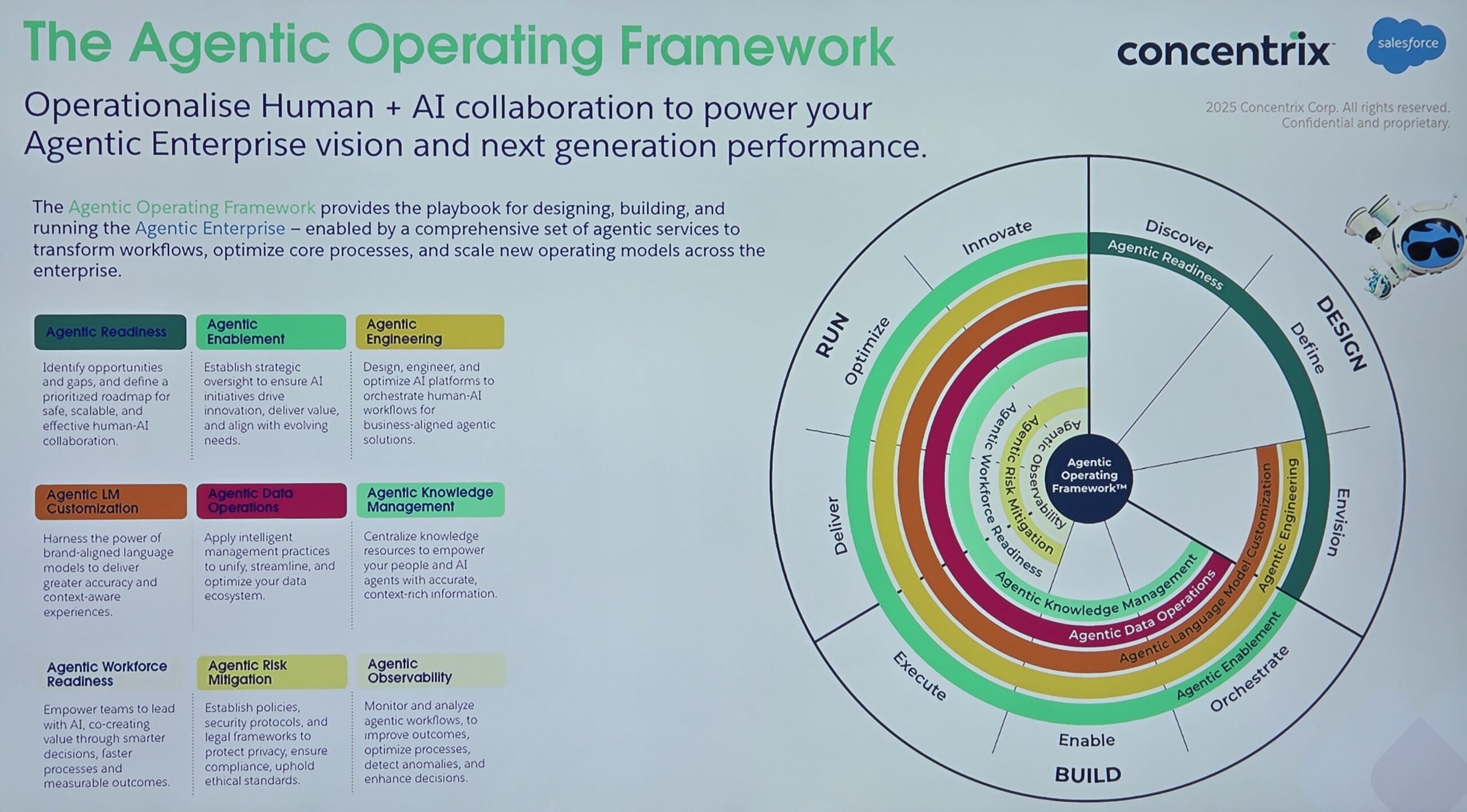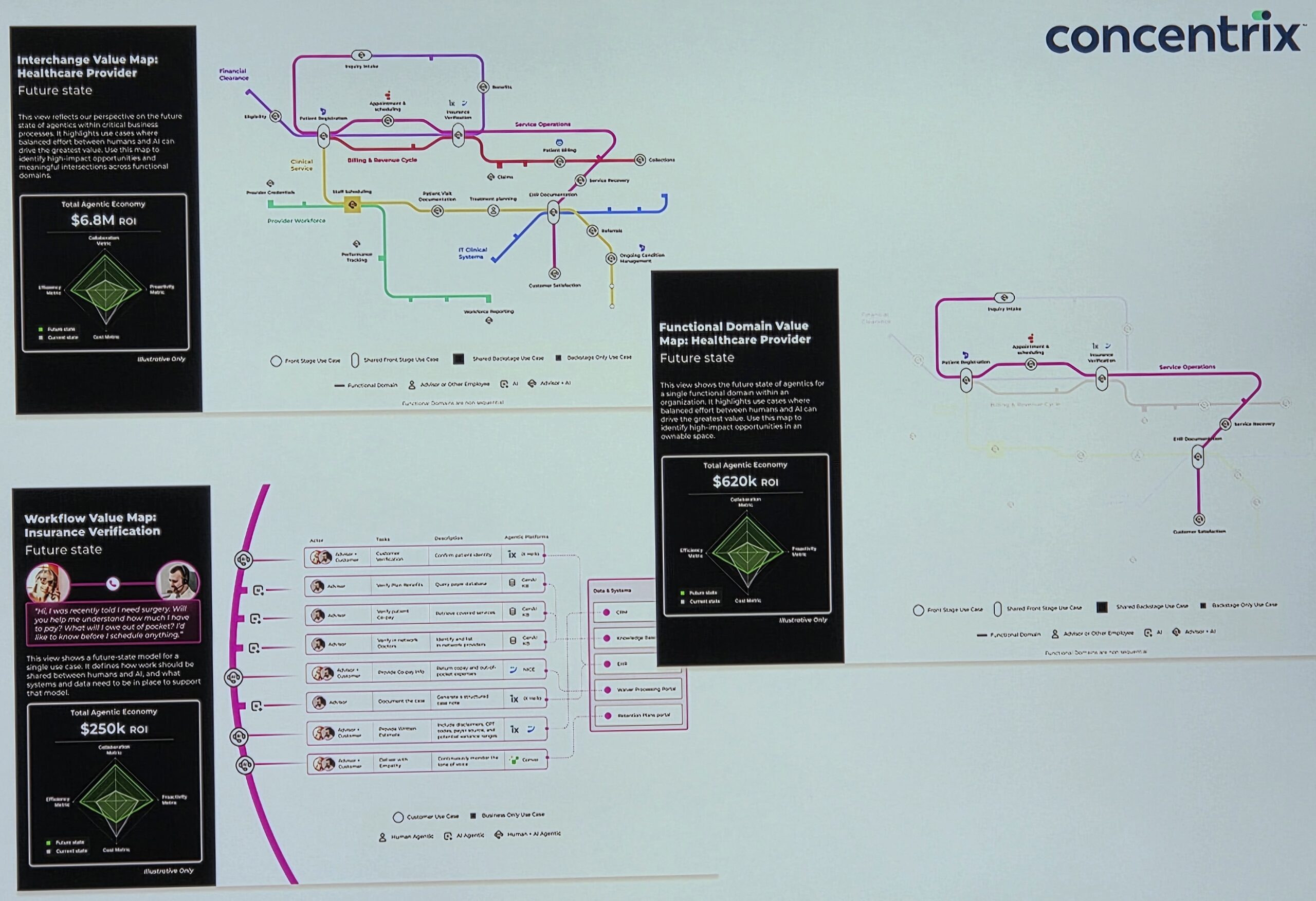
The more I dig down to the coding roots of artificial intelligence, the more I see how it’s portrayed badly. The sheer complexity of its variations is often what makes much of the media coverage and commentary fluffy and difficult to make sense of. Things are either totally absent from the conversation or massively overstated.
On one side, we hear that AI will fix the entire world, usually from those investing in it. On the other that, it will destroy the world, often from those who fear it will damage their livelihoods. What is frequently missing is a discussion about the practical realities. 1
One of the most useful ideas I have taken from the course I am currently working through is this:
A large language model is essentially the average of the internet at a given point in time, based on the data available to it. It is a snapshot of that collective content. As a result, it tends to produce the average of what it has seen.
This helps explain why very senior managers and decision-makers in specialist fields often find it so impressive.
Imagine you are a high-ranking director in a marketing company. You own the business, but you do not personally carry out day-to-day marketing work. You write a piece of marketing copy and ask AI to improve it or turn it into a banner. You receive a result that is noticeably better than your original draft. But because actually writing marketing copy is not your core discipline (you are a people and finance manager), the output feels great.
However, what you have received is not brilliance. It is the average of what the model can produce based on its training data. If ‘average’ is all you need, and you need it consistently, that can be perfectly adequate, and AI is perfect for you.
Now organisations can improve results by feeding AI more relevant information. Take insurance as an example. If you want AI to act as a claims handler and assess whether claims are fraudulent, an off-the-shelf model will initially reflect the broad average of internet knowledge. But if you provide it with your historical claims data, including cases that subject matter experts have identified as fraudulent and the reasoning behind those decisions, performance improves.
Even then, it will only ever reflect the average of what your company has historically done. That is the key point.
There is a great deal of discussion about AI learning. In reality, AI models learn from human-generated data. They can extrapolate faster and at a greater scale than people, but they do not possess judgement in the human sense. They are bound by patterns in the data they have been given.
It is excellent where you want a consistent, nearly repeatable, broadly competent output. It reduces peaks and troughs. It gives you a solid baseline answer time and time again.
If you want true excellence in quality, AI on its own will not deliver that. It can enhance your experts by giving them a strong starting point rather than a blank page. Your specialists still need to review, refine and apply judgement.
Note: I have not suddenly become an AI expert; I am just elbows deep in the very serious “end-to-end AI engineering” by Swirl AI. I would recommend it to anyone that wants to get past the glossy rubbish about AI.
- Not the environmental ones; we all know they are a nightmare.[↩]